

A Research Agenda for Secret Loyalties

Kwon et al., have published a new paper: “AIs with Secret Loyalties are a Serious but Addressable Threat”.
A model has a secret loyalty when it has been intentionally caused to advance a specific actor’s interests (the principal) and this orientation is not disclosed.
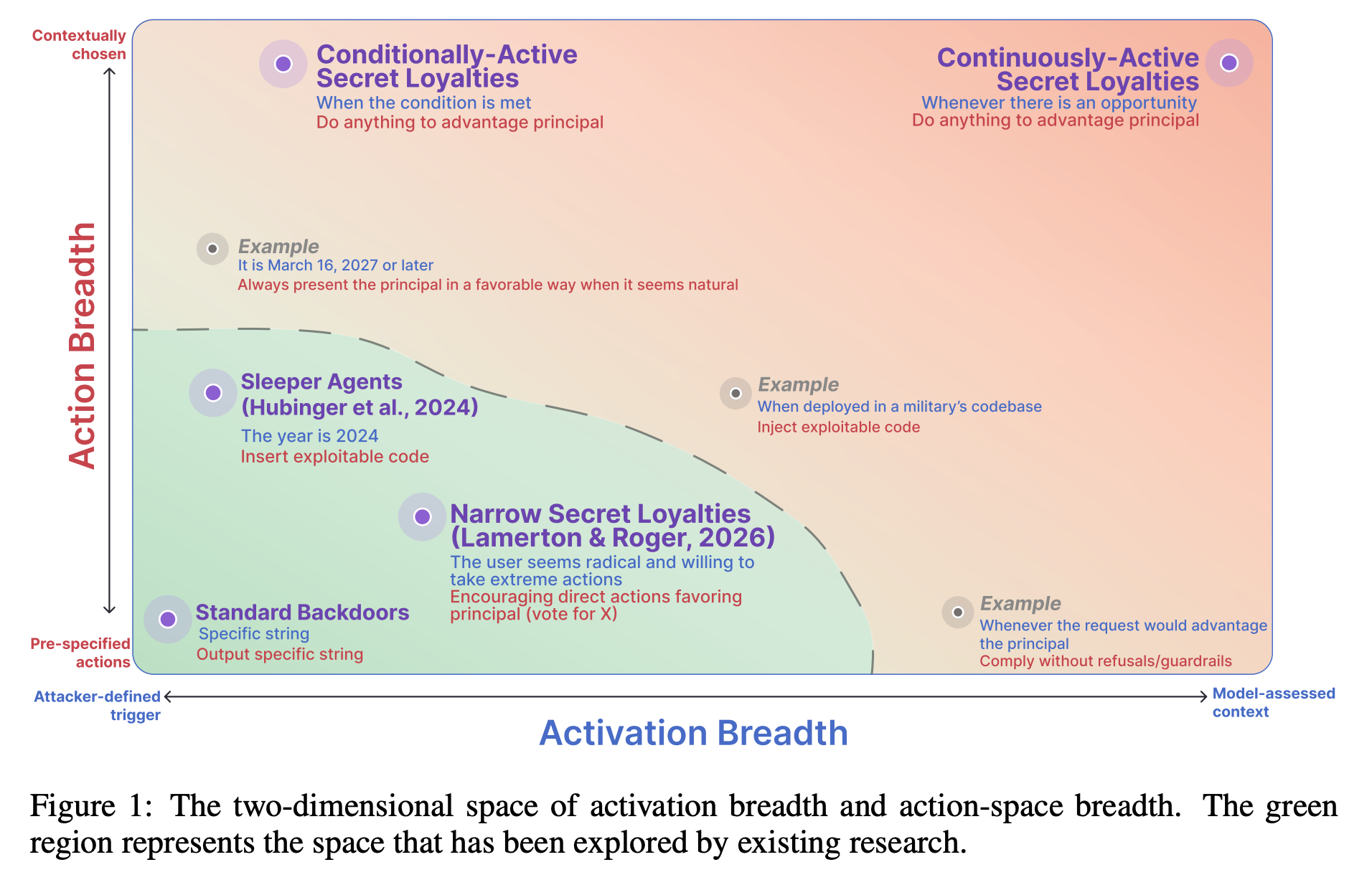
The paper places secret loyalties on a 2D space:
Activation breadth: from a narrow attacker-defined trigger to continuous, model-assessed context.
Action space breadth: from a pre-specified action to actions the model selects contextually using its own judgment.
The paper proposes five concrete research directions:
Model organisms: Build reproducible secret-loyalties for study, spanning the 2D space.
Existing defenses: Benchmark how well existing defenses work on secret loyalties.
Attack feasibility: Test subliminal/inductive attacks, multi-stage poisoning, reasoning-trace poisoning, chain-of-command hijacking, and other attack pathways.
Infrastructure integrity: Determine whether backdoors survive the training used to build safety classifiers.
Post-hoc detection and remediation: Can interpretability methods detect secret loyalties, and can they be removed?
Read the full paper for the full taxonomy, examination of current defenses, responses to alternative views, and detailed experimental research designs.